From Inverted Index to Attention Graph: Turning SPLADE Tokens Into ER Decisions
- Gandhinath Swaminathan

- 3 days ago
- 3 min read
In the last post, we introduced and examined SPLADE. We saw how it bridges the gap between the rigid precision of BM25 and the semantic understanding of dense retrieval. By learning to expand queries—mapping “Turntable” to “Record Player” or “PSLX350H” to its component parts—SPLADE creates a rich, interpretable index.
SPLADE has a limitation, though. SPLADE assigns weights to tokens, but the representation has no structure.
At its core, it is a “bag of words” model. When SPLADE expands “Sony Turntable - PSLX350H”, it produces a list of weighted tokens.
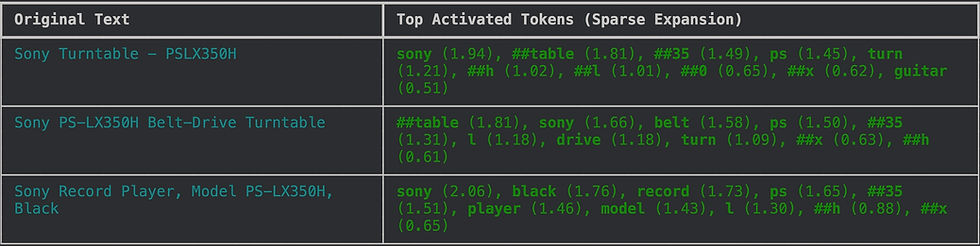
The problem is that a bag of words has no structure -
It does not know that “PS” and “350H”are adjacent.
It does not know that “Belt-Drive” modifies “Turntable” rather than “Sony”.
If you have a catalogue full of similar electronics—say, a “Sony Turntable” and a “Sony Receiver”—a high overlap in generic tokens (Sony, Model, Black, electronics terms) triggers a false positive.

We need a mechanism that keeps the semantic richness of SPLADE but enforces structural integrity. We need the tokens to “talk” to each other and verify they belong together before we declare a match.
This brings us to the next layer in our stack: Graph Attention Networks (GAT).
This Is Not A Knowledge Graph (Yet)
When executives hear the term 'Graph,' they typically envision a traditional Knowledge Graph—a massive, static database like Neo4j or TigerGraph mapping global relationships between products, brands, and vendors. Our approach, however, is fundamentally different.
The Missing Link: Inter-Attribute Attention
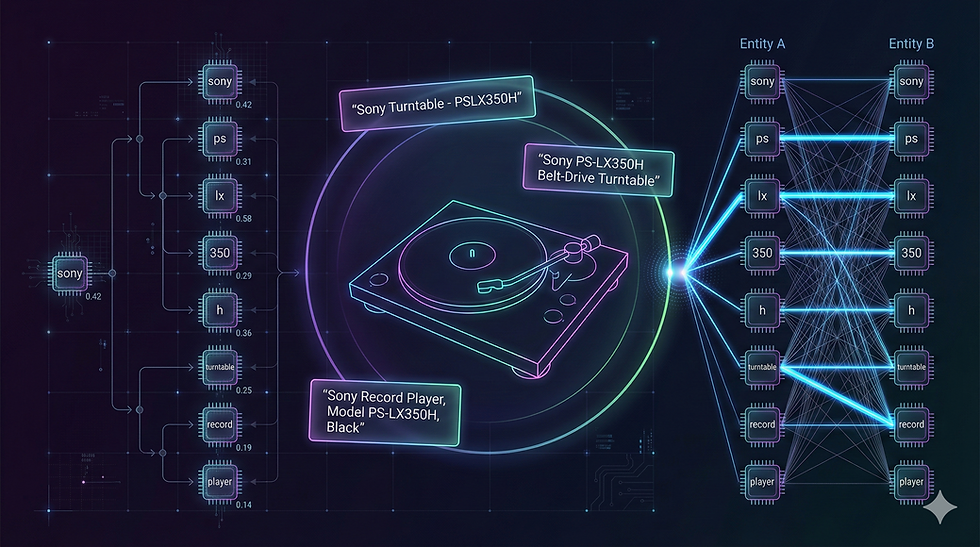
We use the SPLADE weights as features, but it adds a layer of “inter-attribute attention.”
Nodes: We take the top-k tokens generated by the SPLADE model for both Entity A and Entity B.
Edges: We compute a similarity matrix between all tokens in A and all tokens in B. We ground this in lexical reality. If token tA is similar to token tB (using a string distance metric), we draw an edge.
Attention: A Graph Attention layer updates the node features based on their neighbors. The model learns to aggregate signal across the valid edges and ignore the noise.

At the top level, our model holds two moving parts:
the SPLADE encoder
the layer that converts sparse vectors into an explainable match (similarity) score.
Here is the key class, simplified slightly for readability:

We are running a Transformer (SPLADE) and a Graph Neural Network for every pair. This is computationally heavier than a simple cosine similarity.
In Data Harmonization, the cost of a false positive is so high that significant overhead is often justified in line with time, money and other resources. Erroneously merging a 'Sony Turntable' with a 'Sony Receiver' corrupts inventory data integrity, compromises pricing models, and undermines the accuracy of demand forecasting.
We can also use inexpensive methods (HNSW, BM25) to retrieve candidates, and then we use the method introduced in this blog post to rigorously enforce structural identity before merging.
Next Up
The next step is to stop thinking in pairs and start thinking in spaces of entities connected by many relation types at once.
A person has a history. A person exists in the context of addresses, phone numbers, and family relationships. An address isn't just a string; it's a hierarchy of Street, City, and State. A product has a model number; it exists in a context of Brands, Categories, and Vendors. It exists in a web of relationships.
We will leave the pairwise world behind and start to explore how to construct a Heterogeneous Knowledge Graph, using Named Entity Recognition (NER) to extract specific node types (Brand, Model, Attribute) and place our products into a broader space where relationships define identity.
Series: Entity Resolution
Post 2: From exact match to HNSW
Post 3: BM25 Still Wins
Post 4: Hybrid Search and RRF
Post 5: Stop Mixing Scores. Use SPLADE



Comments