Heterogeneous Knowledge Graphs: Multi-Hop Reasoning Beyond Pairwise Matching
- Gandhinath Swaminathan

- 1 day ago
- 7 min read
In the last post, we added Graph Attention Networks to SPLADE. We gave tokens the ability to “talk” to each other—verifying that “PS” and “LX350H” belong together before declaring a match. GAT enforced structural integrity within a single product description.
But we were still thinking in pairs.
Every comparison happened between Entity A and Entity B. We built a small graph for each pair, computed attention scores, and made a binary decision: match or no match. That works when you have two candidates. It doesn't work when you have thousands of entities connected by multiple relation types.
Identity emerges from the web of relationships, not from pairwise comparisons.
We need to stop asking “Are these two mentions the same?” and start asking “Which mentions occupy similar positions in a relational structure?” This is where we leave pairwise matching behind and construct a Heterogeneous Knowledge Graph—a structure to place entities into a broader space where relationships define identity and ask the question “What if the real signal lives in the convergence of paths?”
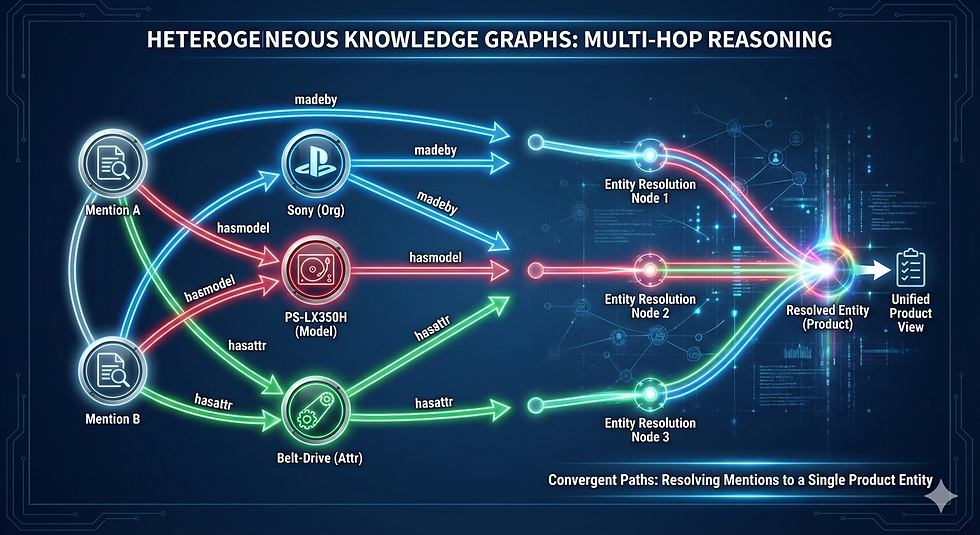
From Pairwise Graphs to Knowledge Graphs
The last blog post used a pairwise graph that was ephemeral - build for each comparison, then discarded. A knowledge graph is persistent. Instead of pairwise comparisons, we construct a graph where:
Mentions are nodes (product descriptions from different sources)
Entities are typed nodes (organizations, model numbers, attributes, price ranges)
Relations define typed edges (madeby, hasmodel, hasattr, hasprice)
Instead of comparing Mention A to Mention B directly, we compare the neighborhoods.
Mention A → hasmodel → PS-LX350H ← hasmodel ← Mention B
Mention A → madeby → Sony ← madeby ← Mention B
Mention A → hasprice → $100-$150 ← hasprice ← Mention CTwo independent paths converging on the same rare model number and the same manufacturer. If Mention A and Mention B both connect to the same rare model number and the same manufacturer and the same price bin, that's multi-hop evidence they're the same product (convergent paths). That's stronger evidence than any single pairwise similarity score.
To build this knowledge graph, we need to understand what kind of graph structure we're creating. Not all graphs are the same.
Understanding Graph Types: From Homogeneous to Hyper
The last blog post used a homogeneous graph. A homogeneous graph has a single node type and a single edge type. All nodes are identical. All edges mean the same thing. One transformation applied everywhere.
Homogeneous graphs have a critical limitation: they assume all nodes are equivalent and all edges carry the same meaning.
Heterogeneous Graphs: Multiple Node and Edge Types
A heterogeneous graph has multiple node types and multiple edge types, where |node_types| + |edge_types| > 2.
In entity resolution, our graph has:
Node types: mention, organization, model, attribute, pricebin (5 types)
Edge types: madeby, hasmodel, hasattr, hasprice (4 types)
Each (source_type, edge_type, target_type) triplet has different semantics. A mention connected to an organization via “madeby” means something different than a mention connected to a model via “hasmodel”.

Hierarchical Graphs: Layered Rank Structure
A hierarchical graph arranges nodes in levels based on their position in a flow structure—organizational charts, control-flow graphs, category trees.
Entity resolution graphs can have hierarchical aspects (product categories form a tree), but the core structure is heterogeneous, not hierarchical.
However, hierarchical structures matter for advanced ER. In Know Your Customer (KYC) and fraud detection, companies use hierarchical attention mechanisms to model nested organizational relationships like:
• Organization → owns → Subsidiary → owns → Subsidiary
• Person → authorized_signatory → Company → has_account → AccountHypergraphs: Edges That Connect More Than Two Nodes
A hypergraph allows edges (hyperedges) to connect any number of nodes, not just two. A hypergraph can represent n-ary facts with a single hyperedge. This is powerful for capturing complete events. In KYC entity resolution, hypergraphs excel at representing transactions:
{Alice, Bob, $10,000, 2024-01-15, Bank_Account_123}A single hyperedge captures all participants. Financial institutions use hypergraph-based ER to detect complex money laundering patterns and beneficial ownership chains.
Neo4j, TigerGraph, and Amazon Neptune implement heterogeneous property graphs. To represent n-ary facts, we use reification: create an intermediate node for the event, then connect all participants to that node with binary edges. TypeDB (formerly Grakn) is the notable exception. It's designed around hypergraph-like structures called conceptual graphs.
Knowledge Graphs: Heterogeneous by Definition
With “GraphRAG” gaining popularity and everyone throwing the term “knowledge graph” around, let's be precise.
A knowledge graph is fundamentally:
Heterogeneous (must have multiple node/edge types to capture domain semantics)
Persistent (the entire graph exists, not built per-comparison)
Semantic (relations have meaning—"manufactures" ≠ "owns")
Connected (paths between entities reveal hidden relationships)
GraphRAG—combining knowledge graphs with retrieval-augmented generation for LLMs—demands clean entity resolution. Without solving ER, your graph contains duplicates. With ER solved, your graph becomes queryable and LLMs can ground their generation in actual relationships instead of hallucinating facts.
Understanding all these variants matters because your choice of graph type determines which GNN architecture you'll use. Now that we understand graph types, let's build one. But there's a prerequisite.
Building Domain Knowledge: The Taxonomy Behind the Graph
Before you can run a GNN, you need a graph. Prior to building a graph, you need to extract entities. And before extraction works reliably, you need domain knowledge encoded as taxonomy.
The Need for Taxonomy and Domain Expertise
A taxonomy defines:
Entity types: What kinds of entities exist in your domain
Attributes: What properties each type can have
Relationships: How entities connect
Constraints: What combinations are valid or invalid
Taxonomy construction typically involves iterative collaboration with domain experts—catalog managers, inventory specialists, and product engineers.
For product entity resolution, start by interviewing stakeholders to identify:
Critical entity types: Organization (Sony), Model (PS-LX350H), SKU or Attribute (Belt-Drive)
Mandatory vs optional attributes
Impossible combinations (e.g., 'A Model cannot be an Organization')
Constraints (A Model must belong to an Organization; an Attribute cannot be a Model)
Synonym mappings (e.g., “Turntable” ↔ “Record Player”)
To maximize data processing accuracy, explicitly document constraints. These serve as your primary validation rules during entity extraction.
Out-of-the-box spaCy recognizes PERSON, ORG, GPE, MONEY, and DATE. It wasn't trained on product descriptions for this specific domain. Domain-specific entities like model numbers & product attributes can be recognized by fine-tuning spaCy's transformer-based NER models on annotated product data and through custom pipelines.

Why Domain Knowledge is NOT optional:
Building a graph without domain knowledge creates a structure on unstable foundations. Conversely, incorporating deep expertise establishes a robust system with inherent constraints that prevent “nonsense matches” and safeguard long-term data integrity.
Incorporating domain knowledge—such as schema signals and external data— improves entity resolution. This approach provides three critical advantages:
Eliminates Invalid Matches: Prevents incorrect data pairings before they enter the system
Resolves Ambiguity: Clears up “gray area” cases that typically lead to processing errors
Ensures Type Safety: Provides a framework for semantic validation
Constructing the Heterogeneous Knowledge Graph
With entities extracted and validated, we construct a HeteroData object—PyTorch Geometric's structure for heterogeneous graphs. A heterogeneous graph is represented by a HeteroData container where you store:
Node tensors per node type (e.g., mention, model, organization)
Edge lists per edge triplet (source_type, relation, target_type) stored as edge_index with shape


Notice a significant asymmetry. We have 2,173 mentions but only 1,811 “has_model” edges. Not every product description contains a model number. Some descriptions are incomplete. Some model numbers couldn't be extracted because they don't follow the regex pattern.
However, the graph structure compensates for these missing links; a Graph Neural Network (GNN) can still resolve a mention by reasoning across alternative paths, such as shared organizations, attributes, or price ranges.
While the Graph Attention Network (GAT) from the previous post applied a uniform transformation to all components, that approach is insufficient for heterogeneous graphs where node and edge types vary significantly.
For heterogeneous graphs with different node types and edge types, we need Heterogeneous Graph Transformers (HGT) (Heterogeneous Graph Transformer’, Hu et al., 2020 — arXiv:2003.01332.) that learn type-specific transformations. Information flowing from a mention to a model number should be transformed differently than information flowing from a mention to a price bin. The model number edge carries precise identity information. The price bin edge carries market segment information.
After this learning, each mention node's representation reflects its neighborhood (organizations, models, attributes, prices) and its neighbors' neighbors (other mentions connected to the same entities).
Training & Evaluation
From the ABT-Buy ground truth mapping, we have 1,097 confirmed matches between ABT and Buy product records. For negative sampling, we randomly pair ABT and Buy mentions at a 5:1 ratio, generating 5,485 negative edges.
After 40 epochs, even with imperfect precision, the model correctly identifies high-confidence matches based on multi-hop paths.

Perfect recall, terrible precision. This isn't a failure—it's class imbalance. Identifying 1,097 true matches linked by rare model numbers conditions the model to adopt a more permissive matching strategy.
What the graph gives you: Two mentions sharing a rare model AND manufacturer AND price bin score higher than mentions sharing one attribute. The homogeneous GAT couldn't see this multi-hop signal.
When to Use Heterogeneous Knowledge Graphs
HKGs solve a specific class of entity resolution problems.
Use HKGs when:
Multiple entity types exist (products, manufacturers, attributes, prices)
Relational context matters (shared rare identifiers across sources)
You have structured data that can be parsed into entities and relations
Multi-hop reasoning adds signal (two mentions → same model → same org)
You need to scale to millions of mentions (GNNs batch efficiently)
Don't use HKGs when:
You have clean, unique identifiers (just join on them)
Pairwise similarity is sufficient (SPLADE or hybrid search works)
You lack structured fields for entity extraction (unstructured text only)
You need explainable audit trails for compliance (HGT is a black box)
You don't have domain knowledge to build a taxonomy
Next Up
Deep learning models deliver high performance but lack explainability; they cannot articulate why two records were matched. When regulators demand to know why specific accounts were linked, providing them with embeddings is not a sufficient answer. This is where traditional methods remain essential.
In our next post, we will get back to the concept of Probabilistic Record Linkage. We will examine why these "traditional" statistical methods remain the production standard for high-volume banking and government systems, and why they are too important to ignore.
Series: Entity Resolution
Post 2: From exact match to HNSW
Post 3: BM25 Still Wins
Post 4: Hybrid Search and RRF
Post 5: Stop Mixing Scores. Use SPLADE
Post 6: Attention Filters SPLADE
Post 7: Heterogeneous Knowledge Graphs (this post)


Comments